 VQAonline
VQAonline
Overview
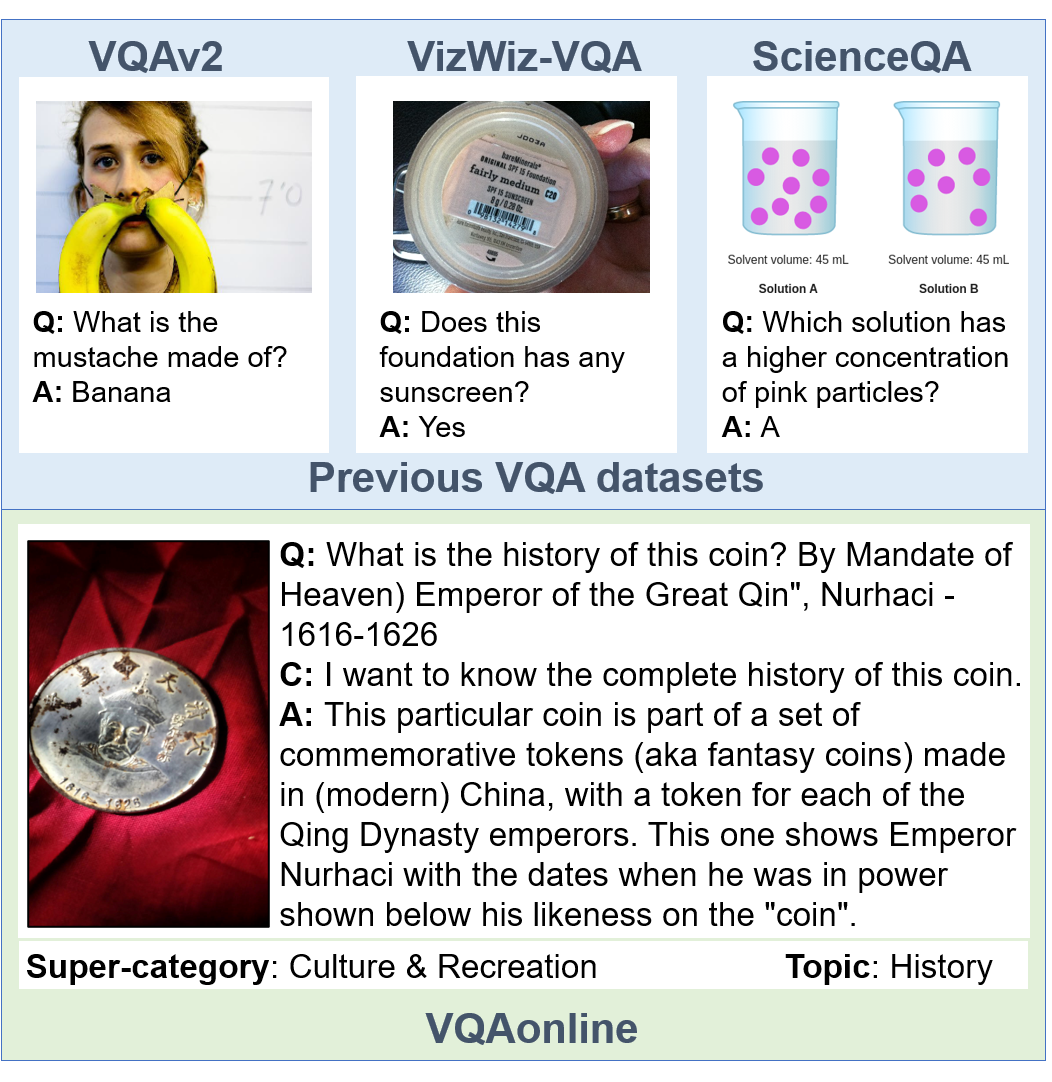
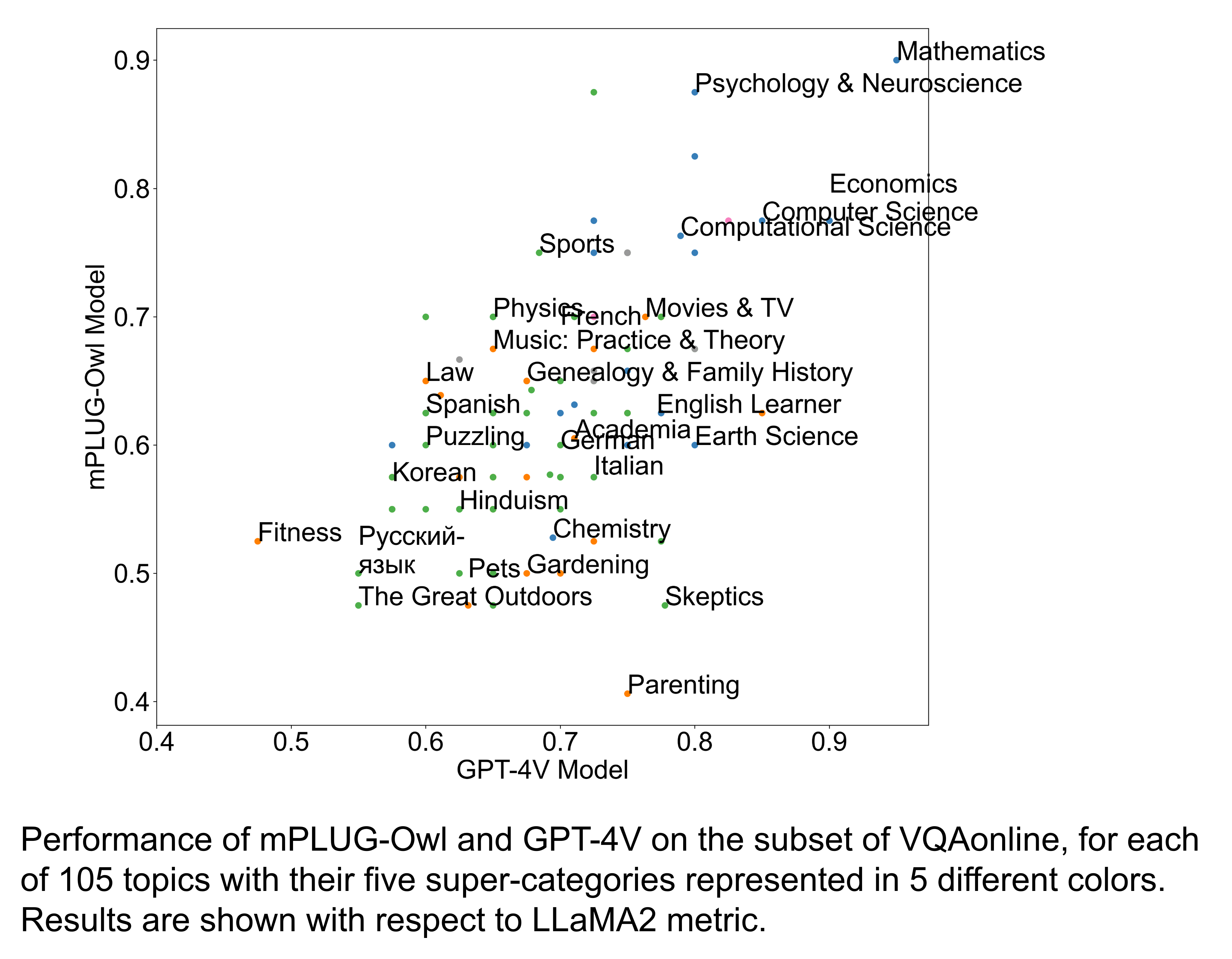
The VQAonline dataset introduces new challenges to current vision and language foundation models (VLMs). These challenges include: (1) Visual questions (VQs) that demand advanced reasoning abilities, such as those found in "puzzling" topics. (2) VQs that require diverse types of knowledge, spanning everyday-life knowledge, fine-grained knowledge, and expert knowledge. (3) Novel image types such as 3D renderings and sheet music, which are the most challenging image types for current VLMs. (4) Multilingual VQs in VQAonline highlights the varying performance of current VLMs across different languages.
VQAonline Dataset
The VQAonline dataset includes:
- Images [PNG files]
- Annotations [JSON files]
- Metadata (number of text detected in the image) [JSON files]
Training, Validation, and Test Sets
- Training Set
- 665 examples
- Validation Set
- 285 examples
- Test Set
- 63,746 examples
Details about each visual question are in the following format:
"image":"VQAonline_00021900.png",
"question":"What is the history of this coin? By Mandate of Heaven) Emperor of the Great Qin", Nurhaci - 1616-1626",
"context":"I want to know the complete history of this coin. ",
"answer":"This particular coin is part of a set of commemorative tokens (aka fantasy coins) made in (modern) China, with a token for each of the Qing Dynasty emperors. This one shows Emperor Nurhaci with the dates when he was in power shown below his likeness on the "coin".",
"topic":"history",
"url":"https://history.stackexchange.com/questions/26573/"
 compared to existing datasets
compared to existing datasets
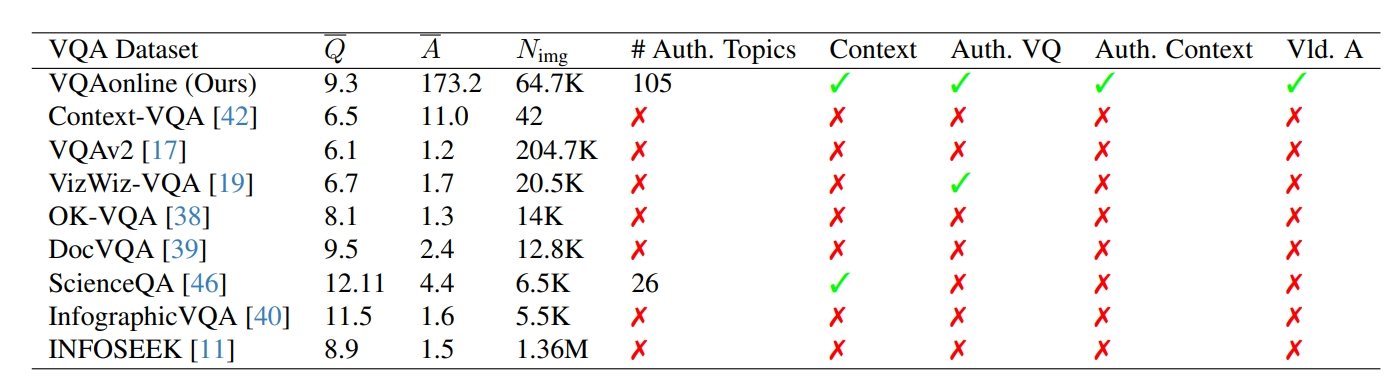
Characterization of existing VQA datasets and our VQAonline dataset in terms of mean question length (i.e., Q), mean answer length (i.e., A), number of images (i.e., Nimg), number of authentic topics (i.e., # Auth. Topics), inclusion of context, inclusion of authentic visual questions (i.e., Auth. VQ), inclusion of authentic context, and inclusion of answers validated by those asking the questions (i.e., Vld. A)).
Data Analysis
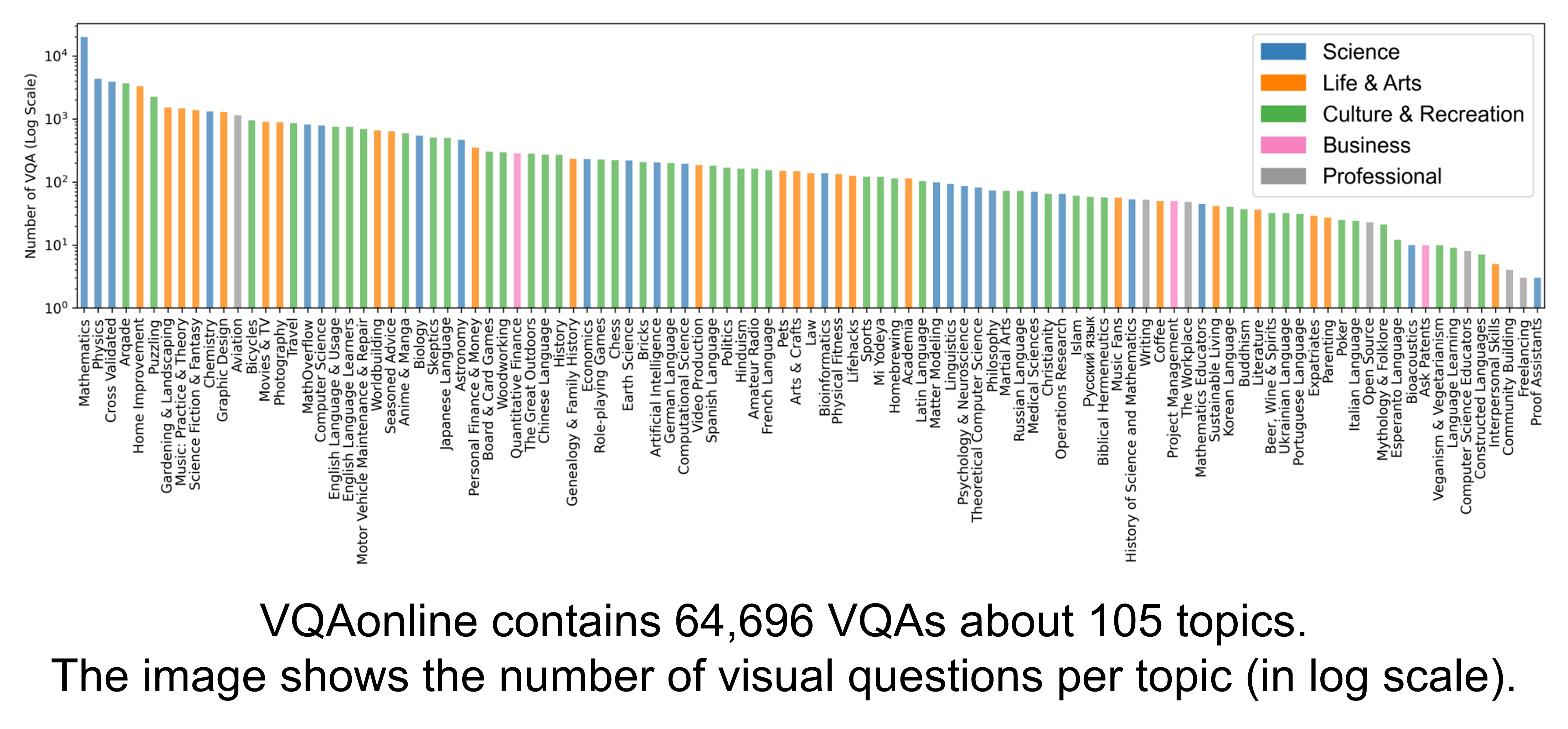
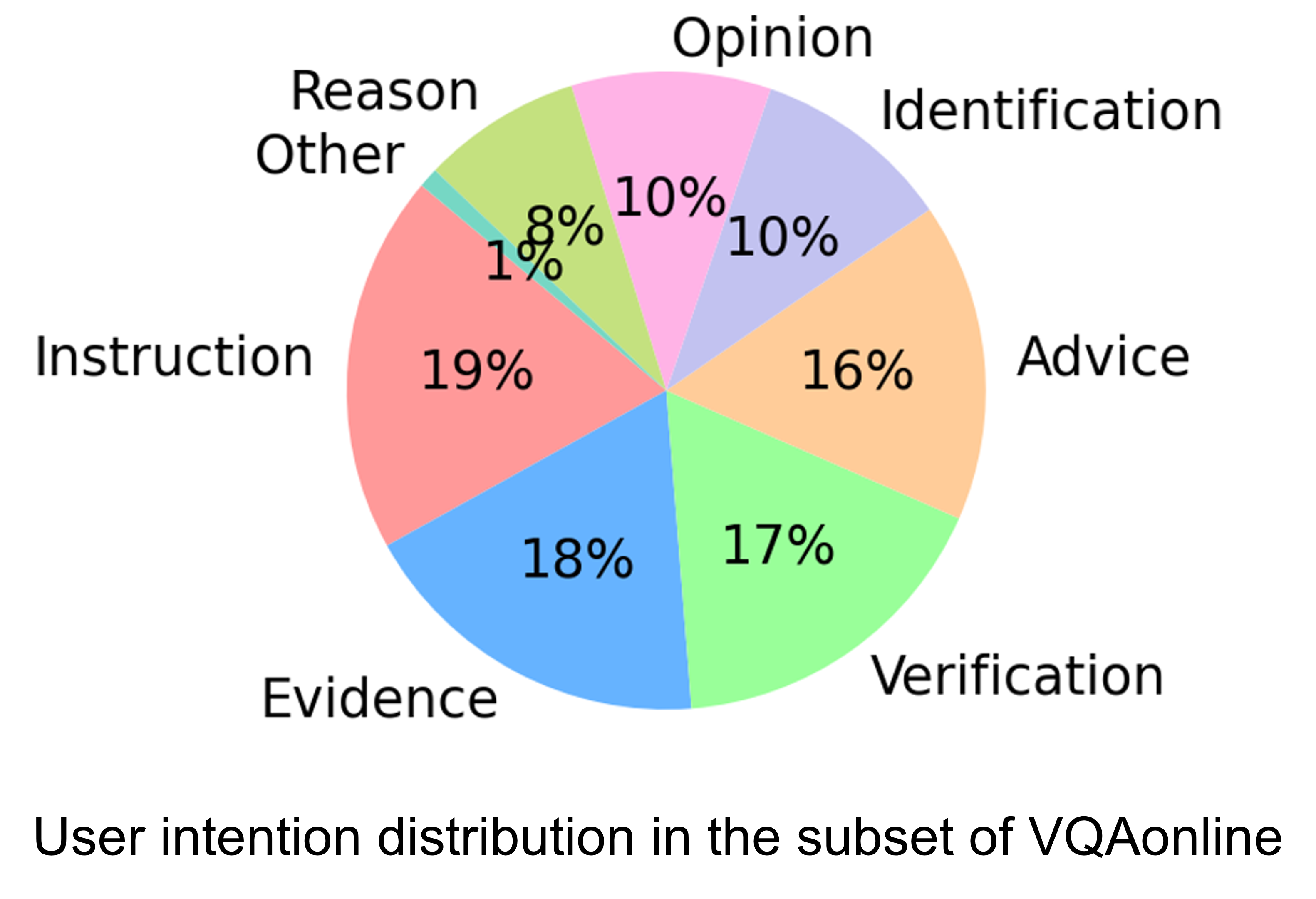
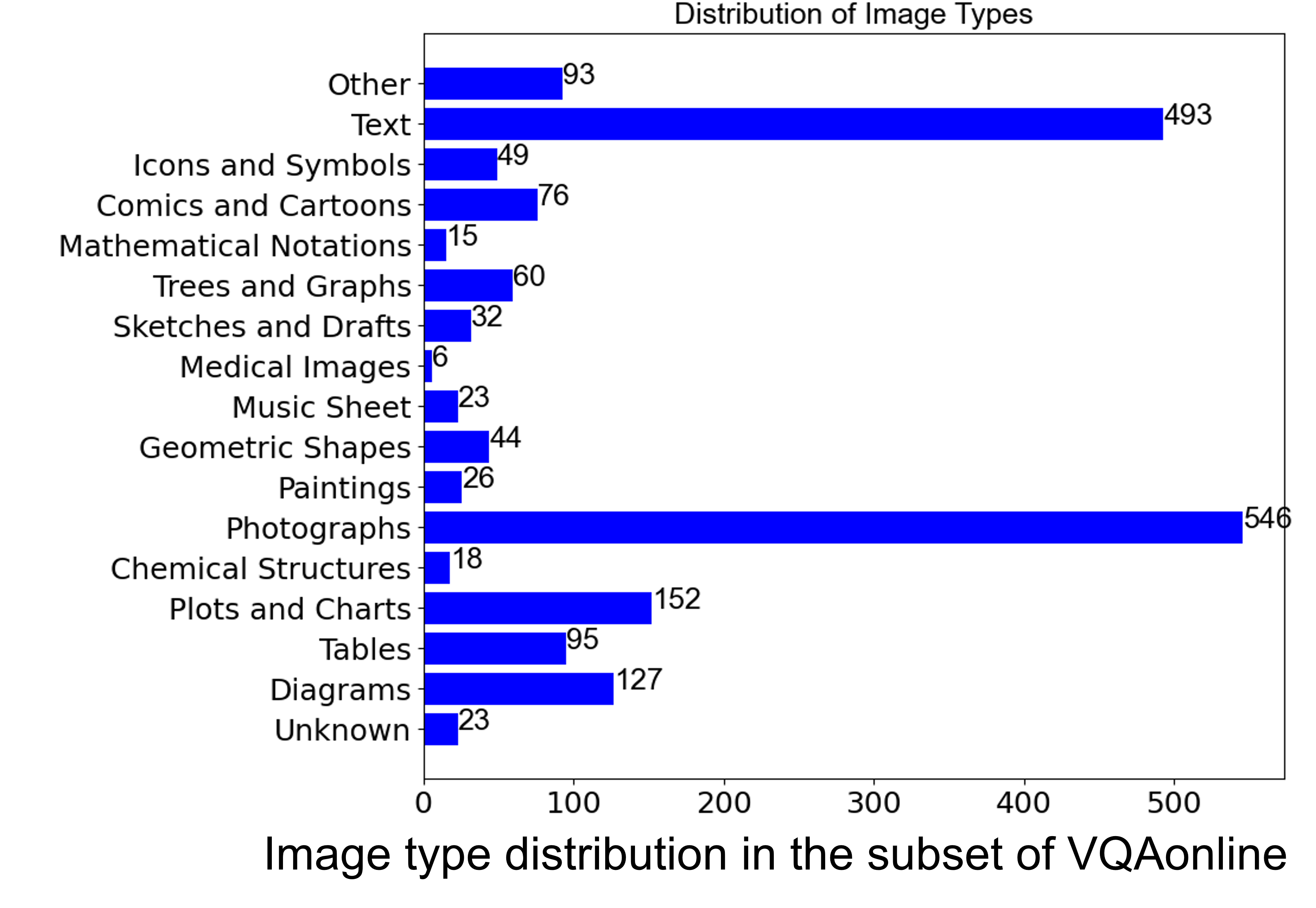
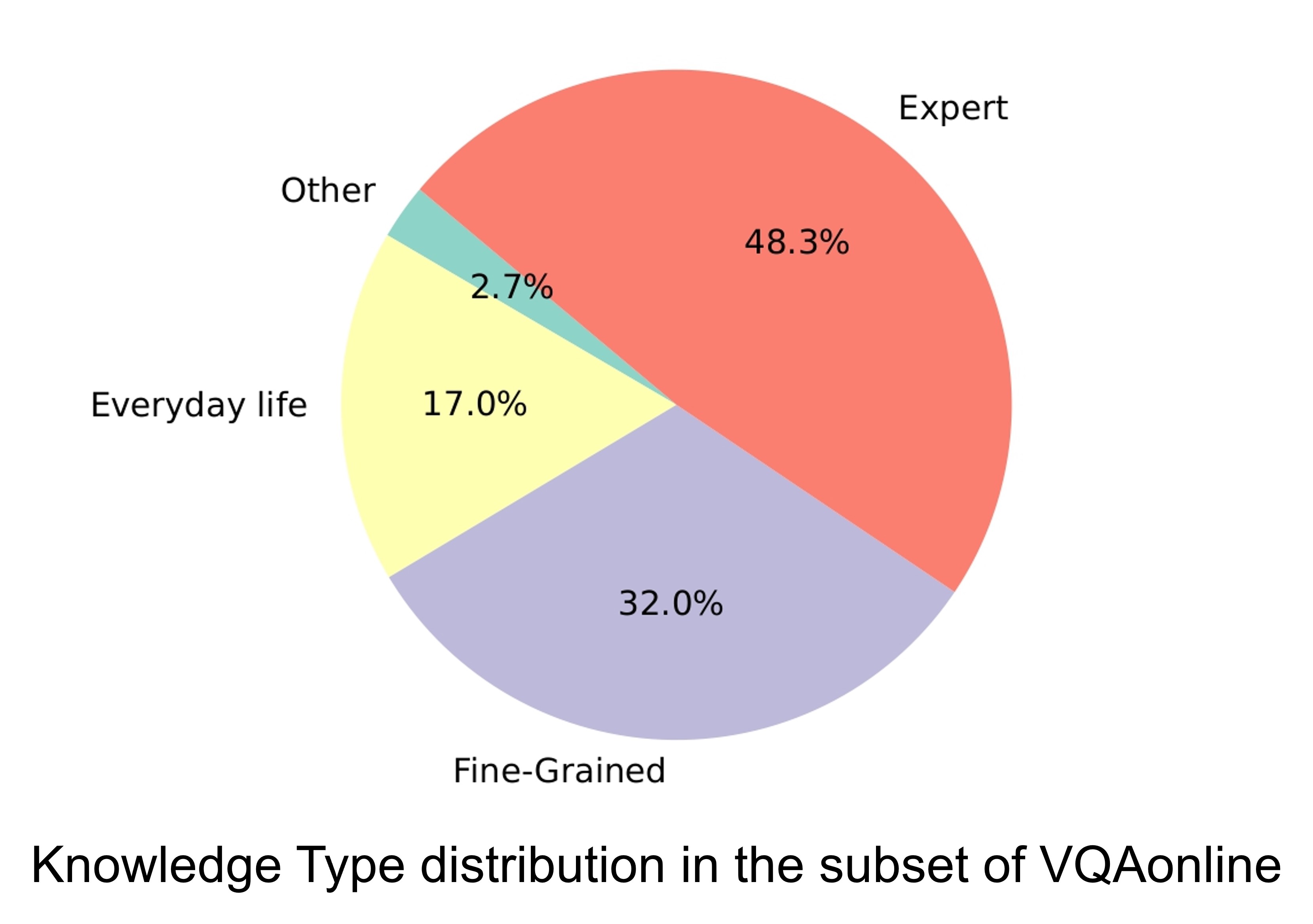
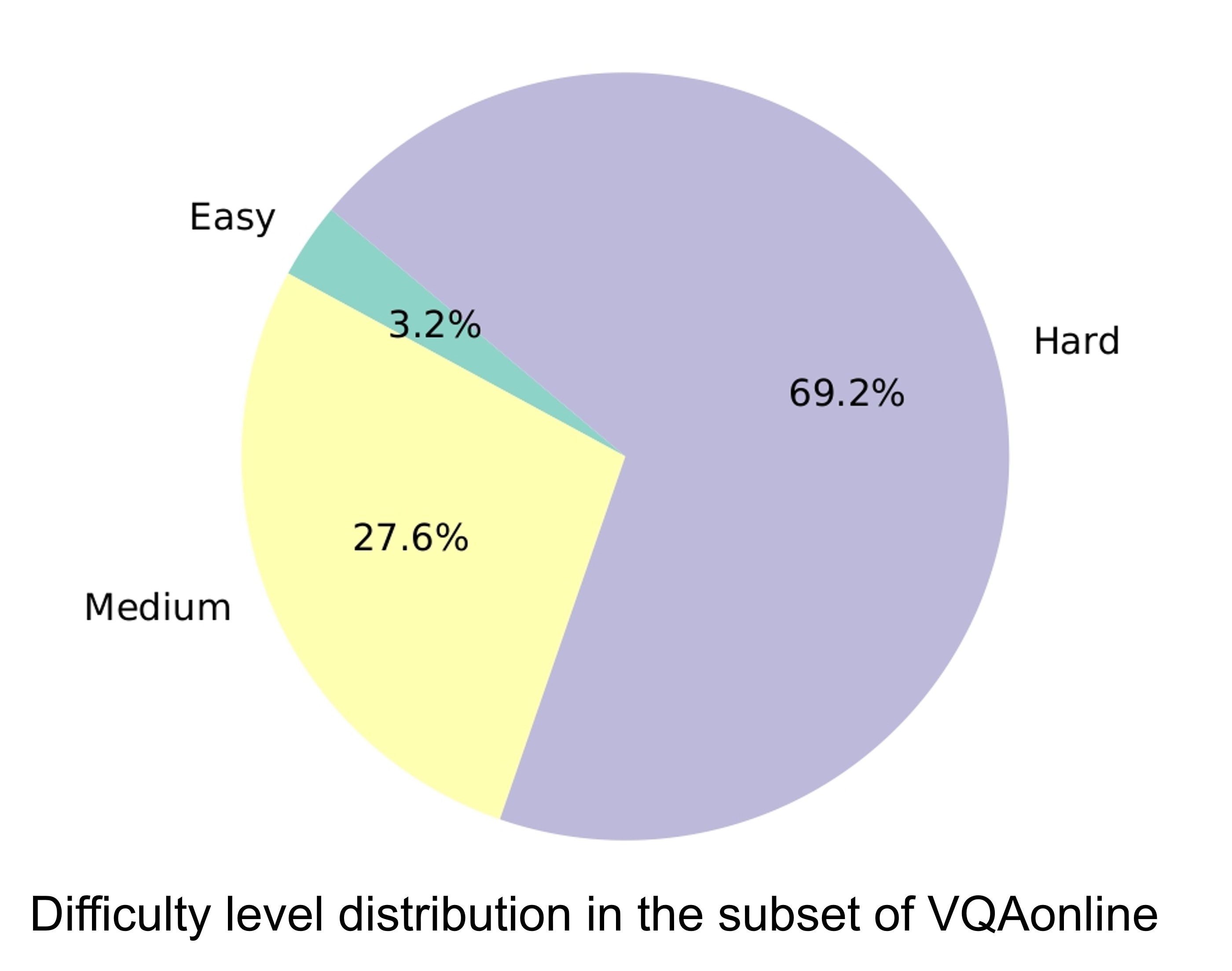
Algorithm Analysis
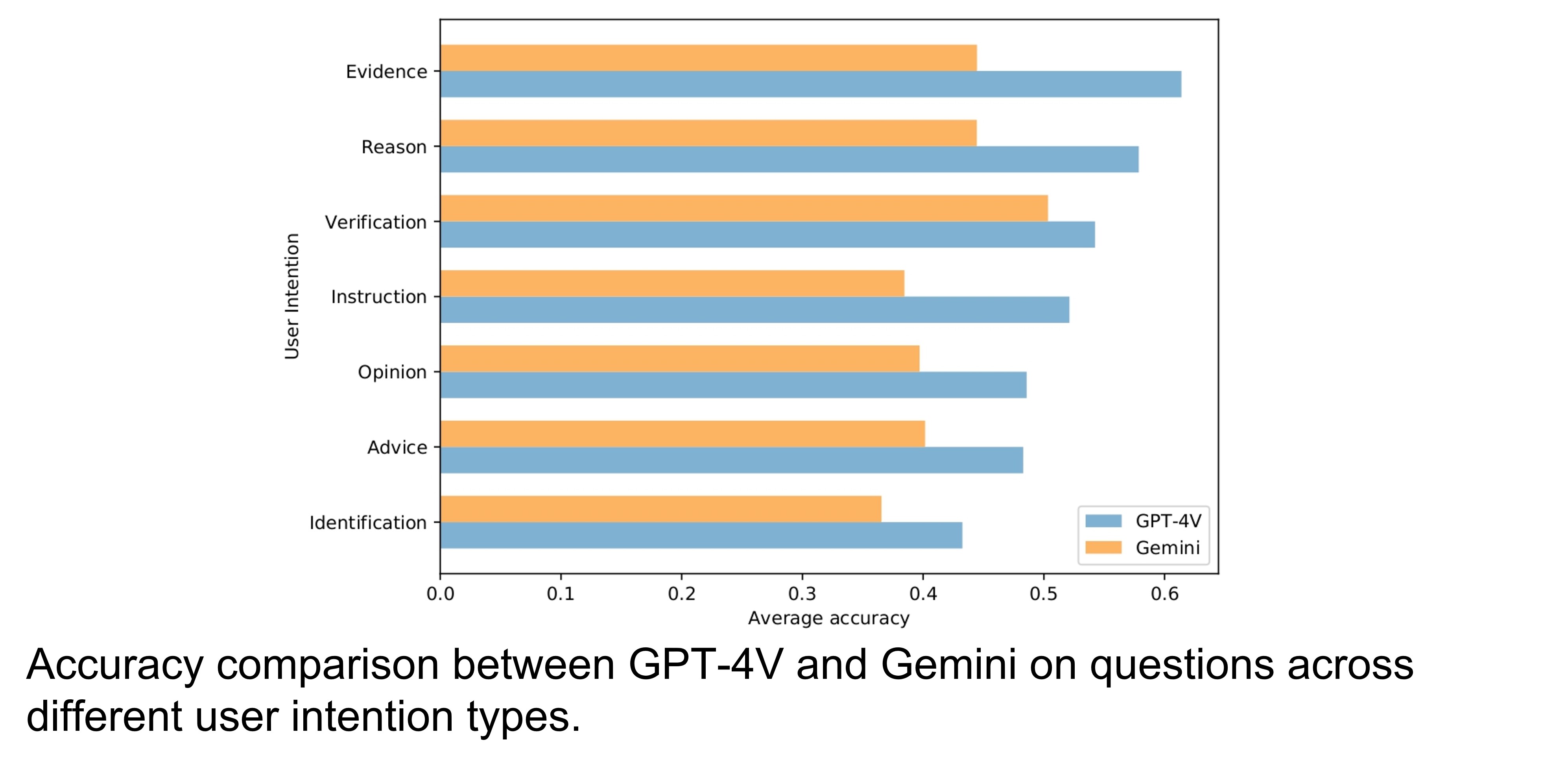
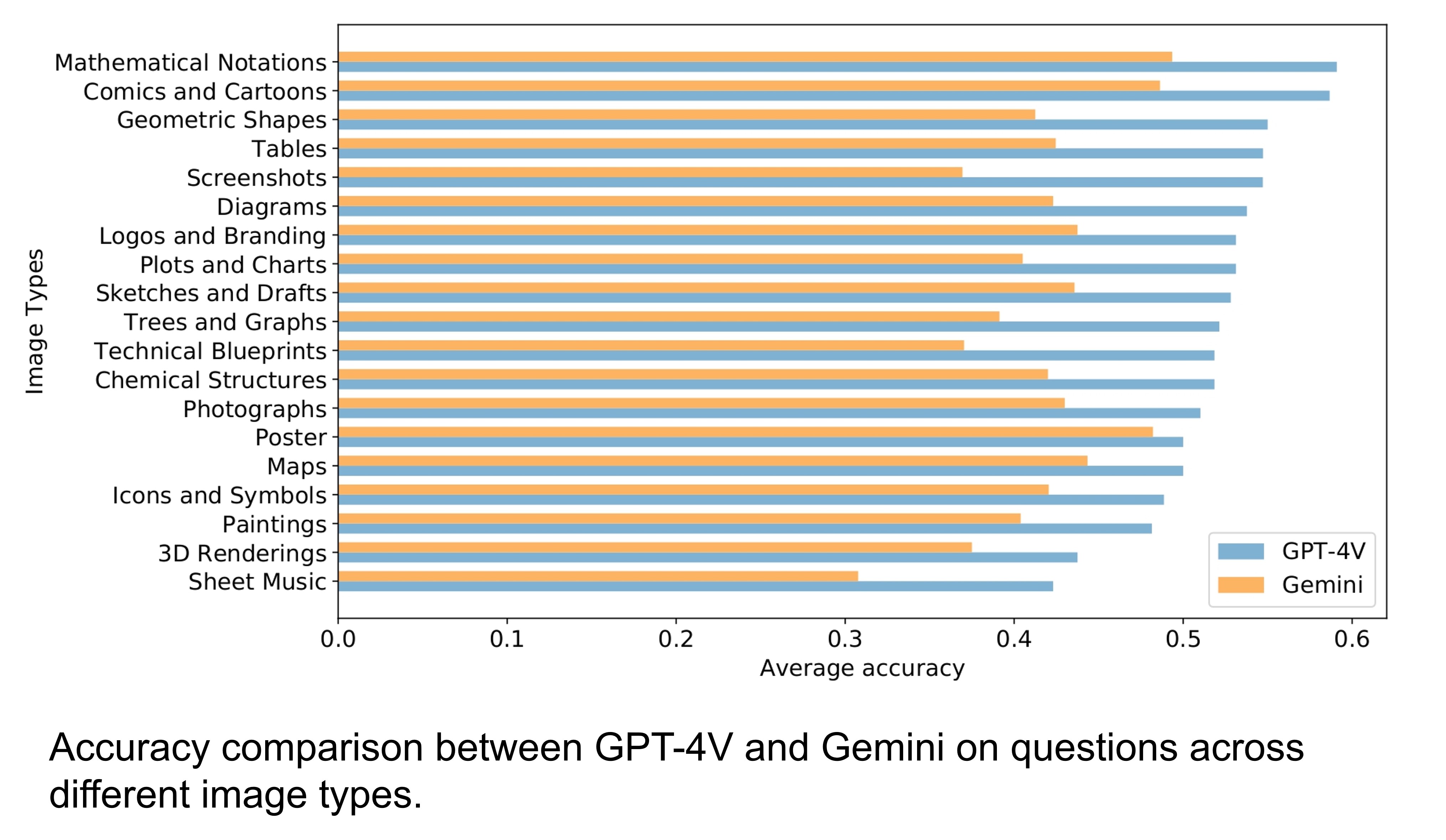
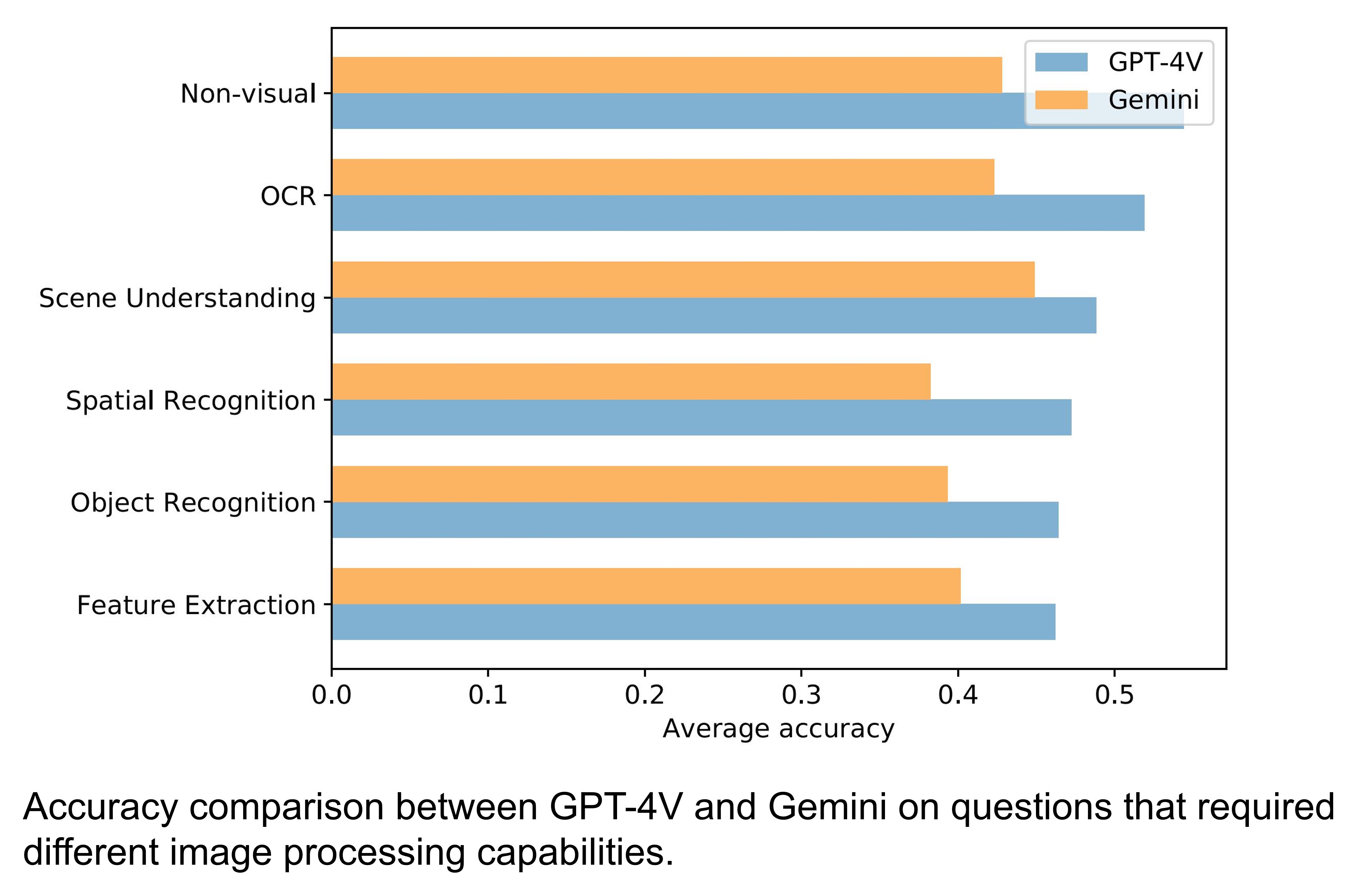
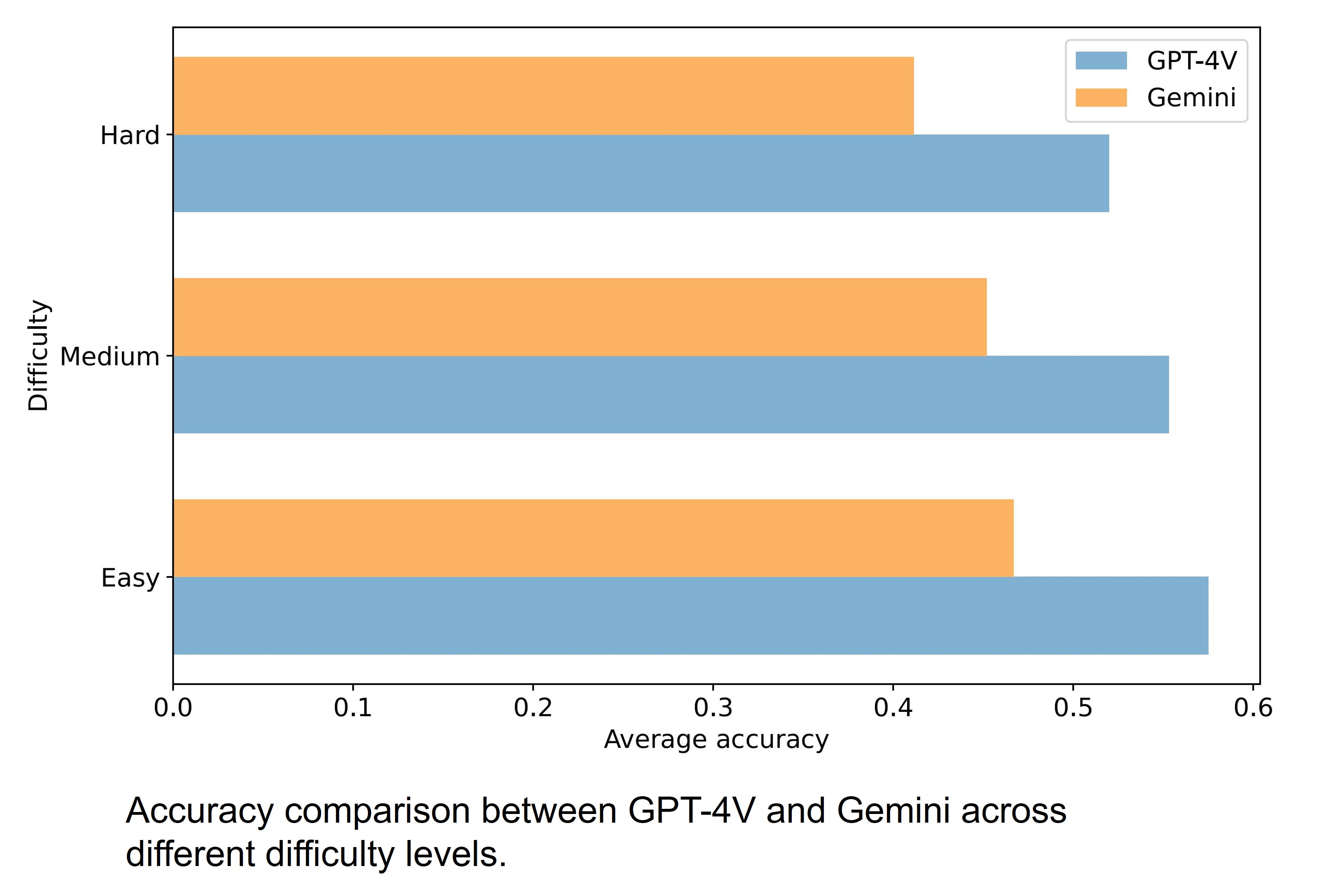
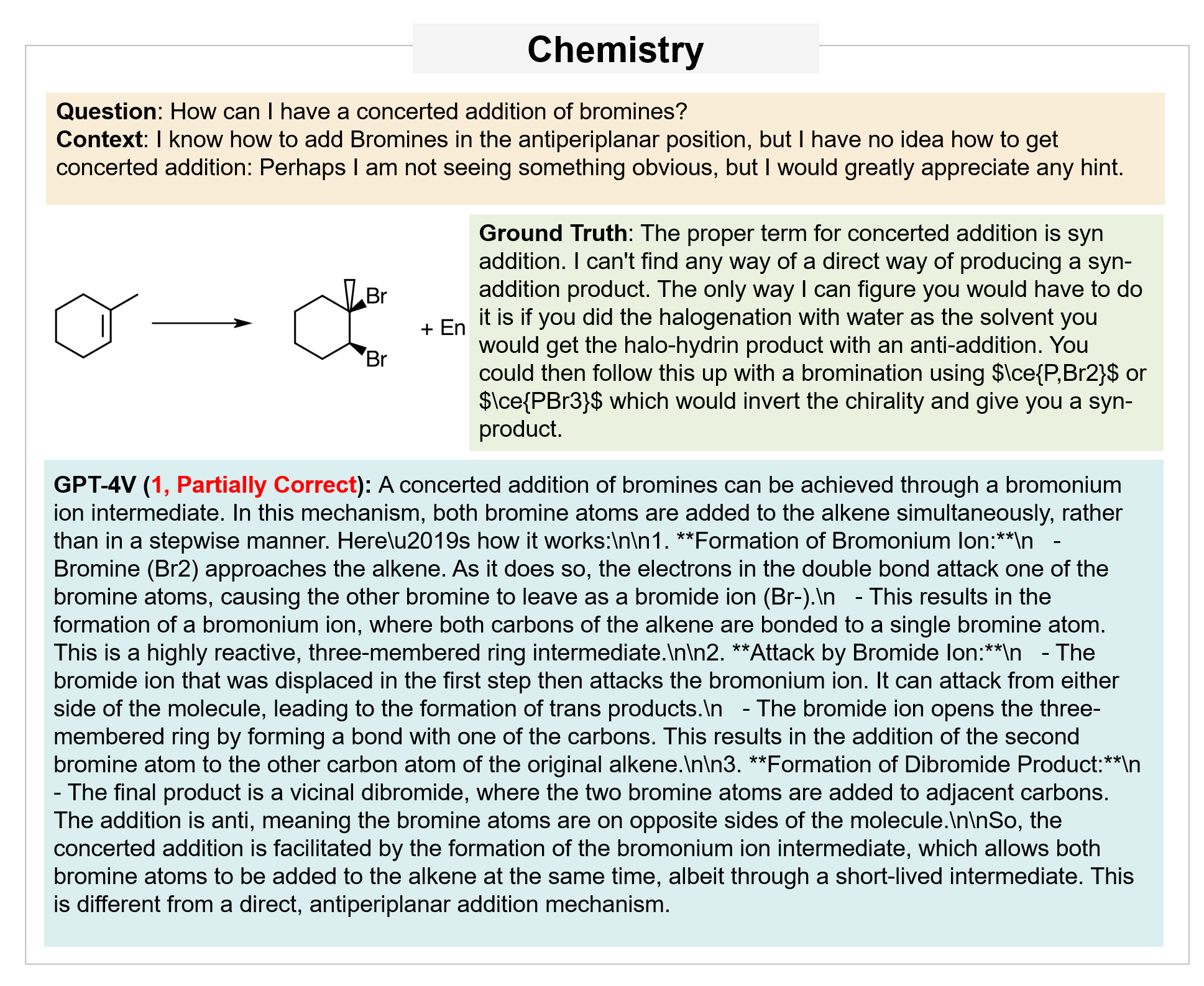
Error Examples





BibTeX
@inproceedings{chen2024fully,
title={Fully authentic visual question answering dataset from online communities},
author={Chen, Chongyan and Liu, Mengchen and Codella, Noel and Li, Yunsheng and Yuan, Lu and Gurari, Danna},
booktitle={European Conference on Computer Vision},
pages={252--269},
year={2024},
organization={Springer}
}
@article{liu2023evalvqaonline,
title={An Evaluation of GPT-4V and Gemini in Online VQA},
author={Liu, Mengchen and Chen, Chongyan and Gurari, Danna},
journal={arXiv preprint arXiv:2312.10637},
year={2023}}